
어쩌다데싸
[유데미(Udemy) 강의 후기] Apache Spark 와 Python으로 빅데이터 다루기 본문

지난 글에 이어 글또 활동에서 무료 수강 기회가 생긴 'Apache Spark와 Python으로 빅데이터 다루기' 강의 후기를 작성해보려 합니다.
1. 강의 수강 배경 & 사전 지식
많은 데이터 관련 공고에서 빅데이터 처리 경험과 스파크 이용 경험을 묻는 것을 보면서, Spark에 대한 이해는 마음에 숙제처럼 남아 있었습니다. 수강 가능 기한이 정해진 이번 기회를 통해 미루지 말고 들어보고자 해당 강의를 신청했습니다.
솔직히 다른 강의 사이트에서도 내돈내산으로 약 115시간짜리 빅데이터 처리 관련 강의를 구매했는데, 당장 일하는데 필요하지도 않고 시간도 워낙 길다보니 들을 엄두가 안 났습니다. 'Apache Spark와 Python으로 빅데이터 다루기' 강의는 7시간 반 정도로 상대적으로 짧은 강의라 해당 강의로 스파크에 먼저 재미를 붙여보고자 했습니다. 강의시간은 짧지만 실습 위주로 구성된 강의라 입문자가 듣기에 오히려 충분한 강의였습니다.
하지만 강의 시간이 짧다 보니 배경이나 이론에 대해 빠르게 지나가는 경향이 있어서, 강의 수강 전에 미리 알아두면 좋을 개념들을 간략하게 정리해보고자 합니다.
1) 빅데이터 분산 처리 배경
현대에는 데이터가 부족한 상황보다는 방대한 데이터를 어떻게 효율적으로 사용해야 하는가 고민하는 상황이 더 많이 있습니다. 빅데이터를 축적할 수 있는 물리적인 환경이 갖춰졌지만, 데이터가 너무 많이 쌓였을 때 이 방대한 데이터를 처리하려고 하니 속도 문제나 다양한 데이터 포맷(CSV, AVRO, Parquet 등) 처리 등 다양한 문제에 직면하게 됐습니다.
이를 처리하기 위해 등장한 것이 yahoo의 하둡(hadoop) 입니다. 분산형 파일 시스템을 기반으로 만들어진 하둡은 HDFS라는 파일시스템, Yarn이라는 리소스 관리, 연산 처리를 하는 MapReduce로 구성됩니다. 하지만 하둡의 HDFS는 DISK I/O를 기반으로 동작하는데, 현대 IT 기술로 진입하면서 해당 빅데이터 처리 방식으로는 실시간 데이터를 처리하지 못한다는 문제가 있었습니다.
2) Spark 등장
스파크(Spark)는 하둡의 빅데이터 처리 방식을 따르면서 속도가 느린 것을 해결하기 위해 등장했습니다. 빅데이터 연산 처리를 할 때 Disk I/O로 처리하는 하둡과 달리 스파크는 인메모리로 처리하기 때문에 실시간 스트리밍이 가능할 만큼 속도가 빨라 크게 주목 받았습니다. 또한 Java, Scala, Python 등 다양한 언어를 지원해서 사용하기 편리하다는 장점이 있습니다.
3) Spark Architecture

스파크는 Driver Program, Cluster Manager, Worker node로 구성되어 있습니다. Driver Program은 애플리케이션의 기본 프로그램을 호출하고 SparkContext를 생성하는 실행 컨트롤러 역할을 수행합니다. (SparkContext의 내용은 강의를 참고해주세요) Worker Node는 Driver가 할당한 작업을 수행하는 역할을 합니다. 할당된 작업을 수행하고 실행하며 성공 또는 실패 상태와 결과를 다시 보고하는 일을 하는데, 각 스파크 애플리케이션에는 자체적인 별도의 실행 프로세스가 있습니다. 마지막으로 Cluster Manager는 스파크 애플리케이션을 실행할 머신 클러스터를 유지 관리합니다.
이러한 구성으로 인메모리 연산 분산 처리가 가능해져 속도가 빨라지게 되었다고 합니다.
2. 강의 구성
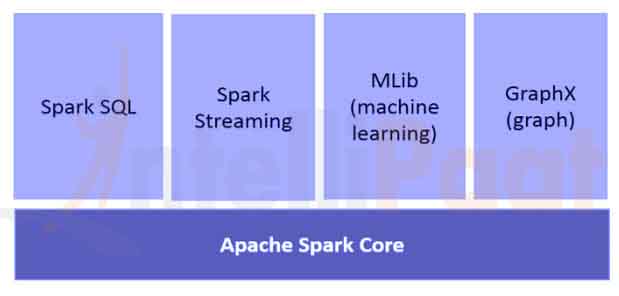
강의는 스파크에 대한 환경 세팅 방법과 개념, 스파크의 구성요소들에 대해 Section을 나누어 설명하는 것으로 구성되어 있습니다. 강의 목차를 살펴보면 아래와 같습니다.
- Section 1 : Spark 시작하기 - 윈도우 중심 환경 세팅 및 실습에 사용할 데이터 다운로드
- Section 2 : Spark 기본 사항 및 RDD 인터페이스 - Spark를 사용하는 이유와 핵심 개념인 RDD에 대한 설명
- Section 3 : SparkSQL - Spark에서 RDD 대신 사용하고 있는 API인 SparkSQL에 대한 설명
- Section 4 : Spark 프로그램의 고급 예제 - 심화된 실습
- Section 5 : 클러스터에서 Spark 실행
- Section 6 : Spark ML을 이용한 머신러닝
- Section 7 : Spark 스트리밍, 구조적 스트리밍 및 GraphX
구성요소 별로 나누어져 있으니 각 파트를 구분해서 이해하기 좋은 구성이었습니다. 또한, 각 Section 마다 실습할 수 있는 코드들이 다양하게 들어 있어 해당 내용을 직접 실행하며 따라갈 수 있다는 점에서 초보자들도 따라가기 쉽게끔 각 파트가 구성이 되어 있습니다.
3. 강의 후기
1) 좋았던 점
- 실습 코드 중심으로 설명해줘서 빠르게 이해하기 좋았습니다. 이론만 이야기 할 때는 개념이 헷갈리지만 이어서 나오는 실습 코드에서 실제로 적용하며 해당 개념을 한 번 더 설명해주다 보니 이해가 안 갔던 개념들도 바로 이해할 수 있었습니다.
- 7시간의 짧은 강의라 부담없이 들을 수 있지만, 꼭 필요한 내용 중심으로 구성이 되어 있어서 스파크에 대해 전반적으로 빠르게 훑을 수 있는 강의였습니다. 짧지만 이해하기 쉽게 요점만 잘 가르쳐주는 느낌이라 처음 스파크를 접하면서 빠르게 이해하고 싶은 초보자들에게 적합한 강의였습니다.
2) 아쉬웠던 점
- 환경설정이 윈도우 중심으로 설명되었는데, 영상대로 따라했지만 오류가 나 진땀을 뺐었습니다. 강의가 중간중간 업데이트 되는 것 같긴 하지만, 환경설정 파트는 좀 예전에 만들어진 강의가 아닌가 하는 의문이 들었습니다. Q&A를 통해 문제를 해결해주고 있지만 초보자 입장에서는 환경설정에서 막히니 다음 강의로 가는 것이 부담되어서 이 부분이 좀 아쉬웠습니다. 저는 결국 맥에서 진행했는데, 맥의 환경세팅 방법이 별도 사이트에서 안내되고 있지만 그것으로는 부족한 감이 있어 결국 별도의 구글링을 통해 환경을 세팅해 진행했습니다.
- 아무래도 7시간의 짧은 강의이다 보니 이론이나 배경에 대한 설명은 상대적으로 부족하게 느껴질 수는 있습니다. 이 부분은 아쉬웠던 점보다는 이론보다 실습 중심의 강의이기 때문에 깊은 이론적 지식을 기대하고 듣는 분들에게는 적합하지 않은 강의인 듯 합니다.
3) 추천하고 싶은 대상
- 초보자도 들을 수 있는 강의이긴 하지만 어느정도 파이썬이나 scala, java 등 스파크를 사용하는데 필요한 언어 중 하나에 대한 기본적인 지식은 갖추고 들어야 실습을 따라가기 좋을듯해, 기본적인 언어 지식은 갖추고 있는 분들께 추천합니다.
- 스파크를 바로 사용해야 해서 짧은 시간동안 실무에 적용할 수 있는 코드를 기대하는 사람에게 추천합니다. 이론적인 깊은 내용을 기대하거나 이미 스파크를 충분히 알고 있는데 더 고급 단계를 기대하는 사람에게는 추천하지 않습니다.
Spark, 항상 공부해야지 생각만 하고 우선순위에 밀려 쉽게 시작하지 못했던 영역이었는데, 글또와 유데미 덕분에 좋은 기회로 접할 수 있었습니다. 짧은 강의를 통해 스파크에 대한 전반적인 이해와 흥미를 붙였으니 이제는 미뤄뒀던 115시간 짜리 강의로 심화된 버전의 공부를 시작할 수 있을 것 같습니다.
< 유데미 - Apache Spark와 Python으로 빅데이터 다루기 바로가기 >
https://www.udemy.com/course/best-apache-spark-python/?couponCode=KEEPLEARNING
참고로 Apache Spark와 Scala로 빅데이터 다루기 강의도 있으니 Scala로 Spark를 이해하고 싶은 분들은 해당 강의로 듣는 것을 추천합니다.
'ETC' 카테고리의 다른 글
| YouTube API 키 발급 및 Python을 이용한 API 요청 가이드 (1) | 2025.03.07 |
|---|---|
| [마케팅 데이터 분석] 퍼널 분석 & KPI (0) | 2025.02.20 |
| [유데미(Udemy) 강의 후기] Python 부트캠프 : 100개의 프로젝트로 Python 개발 완전 정복 (1) | 2024.03.31 |
| [Python] matplotlib 시각화 정리 (0) | 2021.07.13 |
| [Anaconda] 가상환경 만들기 (2) | 2021.07.08 |


